Stable Diffusion
简介:stable diffusion WebUI(以下简称SD)是一个AI图像生成平台。它有多种多样的功能,比较适合想要了解AI绘画并生成图像的同学。本教程将从生成图片开始,到深入原理,你需要比较多的时间来看完
SD原理链接:https://zhuanlan.zhihu.com/p/579454845
AI绘图涉及到自然语言处理,图像处理,GAN神经对抗网络等多种知识
注意:
SD是一个平台,它不能帮助你了解算法原理,只能让你生成和调用模型
本教程仅适用于生成二次元画风和角色,对于生成真人照片和其他画风请自行摸索
由于AI绘画正处于快速上升期,其中的技术日新月异,不能保证其中的任何内容都对齐最新版本,你需要具有较强的自主学习能力
入门
简介:要使用SD平台来进行绘画,首先你需要有一套合适的软硬件和适合的字典来生成对应人物。
入门主要是从环境搭建到基本学会使用SD绘画的基本参数
链接:【AI绘画】从零开始的AI绘画入门教程——魔法导论 - 哔哩哔哩 (bilibili.com)
硬件:
AI绘画对显卡的要求最高,特别是显存占用很高。CPU影响较小,因为计算往往全部交给了显卡。你可能需要16G运行内存和一个固态硬盘来保证SD的开启速度
要使用SD来运行AI模型,你至少需要一张4G显存的显卡,仅生成图片需要8G,训练模型需要12G,RTX20系以上最为合适。如果可以,请尽量使用NVIDIA(英伟达)的显卡而非AMD(超威)的显卡,因为AI的模型训练的加速框架运用到了CUDA,该技术有且只有N卡才能使用。如果你只能使用A卡,建议在Linux上运行才会获得更好的效果
软件:
准备好硬件后,你需要的是给它安装一个操作系统,你可以选择Linux或者Windows。但是我这里只做Windows的教程
你可以选择自行搭建环境,自行搭建环境出现的问题99%都是网络问题
或者选择整合包:https://www.bilibili.com/video/BV1iM4y1y7oA
新手我建议你安装CUDA,直接使用秋葉aaaki大佬的整合包
CUDA可以在NVIDIA官网找到,根据你显卡的型号去安装
到这里,我觉得你应该已经可以运行大佬提供的整合包了:
如果无法成功运行,你可以点击右上角的问号看看论坛和视频
开始文生图
标签
简介:SD平台的主要作用就是要让文字转换成你想要的图片,其他功能都是为这个服务的。想要在SD上生成图片,首先你需要了解什么是Tag(标签)。
在文字生成图片中,一张图片是由多个Tag相互制约形成的,也就是给图片贴标签。在SD中,标签分为正向标签和反向标签。
正向标签:你想要生成的画面
反向标签:你不想要生成的画面
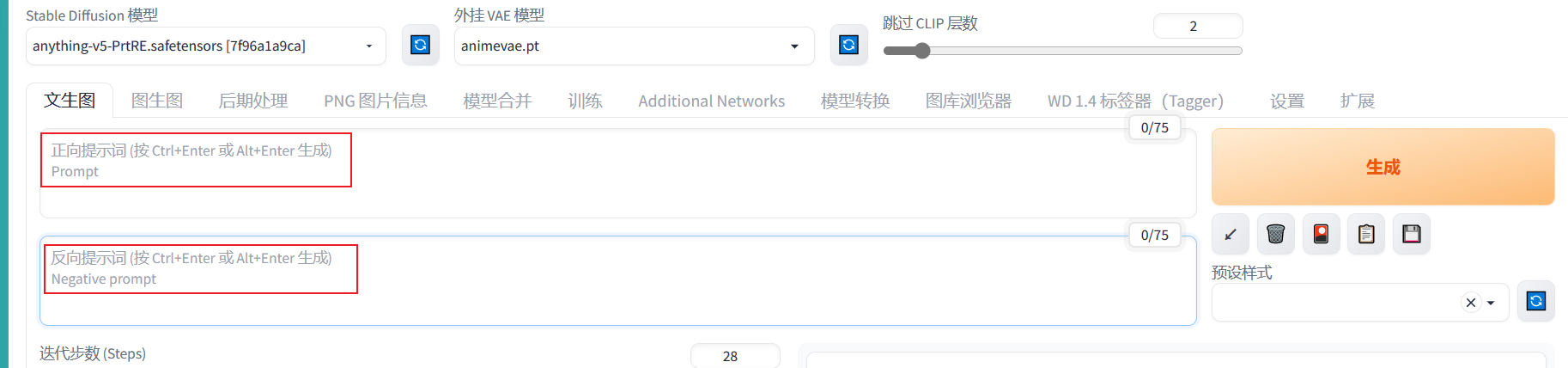
在生成图片的过程中你最好使用英文标签来描述图片,你可以使用句子,但是正常情况下它应该会被语言模型重新提取出句子里的标签词
获取标签
简介:获取标签可以使用整合包里包含的提示语法,也可以使用别的方式来获得一张图片包含的标签。但是由于SD的二次元模型是基于Danbooru这个网站的图片标签集训练出来的,因此所有图片的标签都源自于这个网站
注意:AI生成的图片信息会自动保存全部参数在原图,非AI生成的图片需要经过反推得到标签
在这些网站找到大佬训练的标签模板:Danbooru 标签超市 (novelai.dev),魔咒百科词典 (aitag.top)
正向获取
在插件上获取标签提示
这里可以看到在标签栏输入1就会自动获取当前比较火热的标签,前面的是标签名,后面的是热度
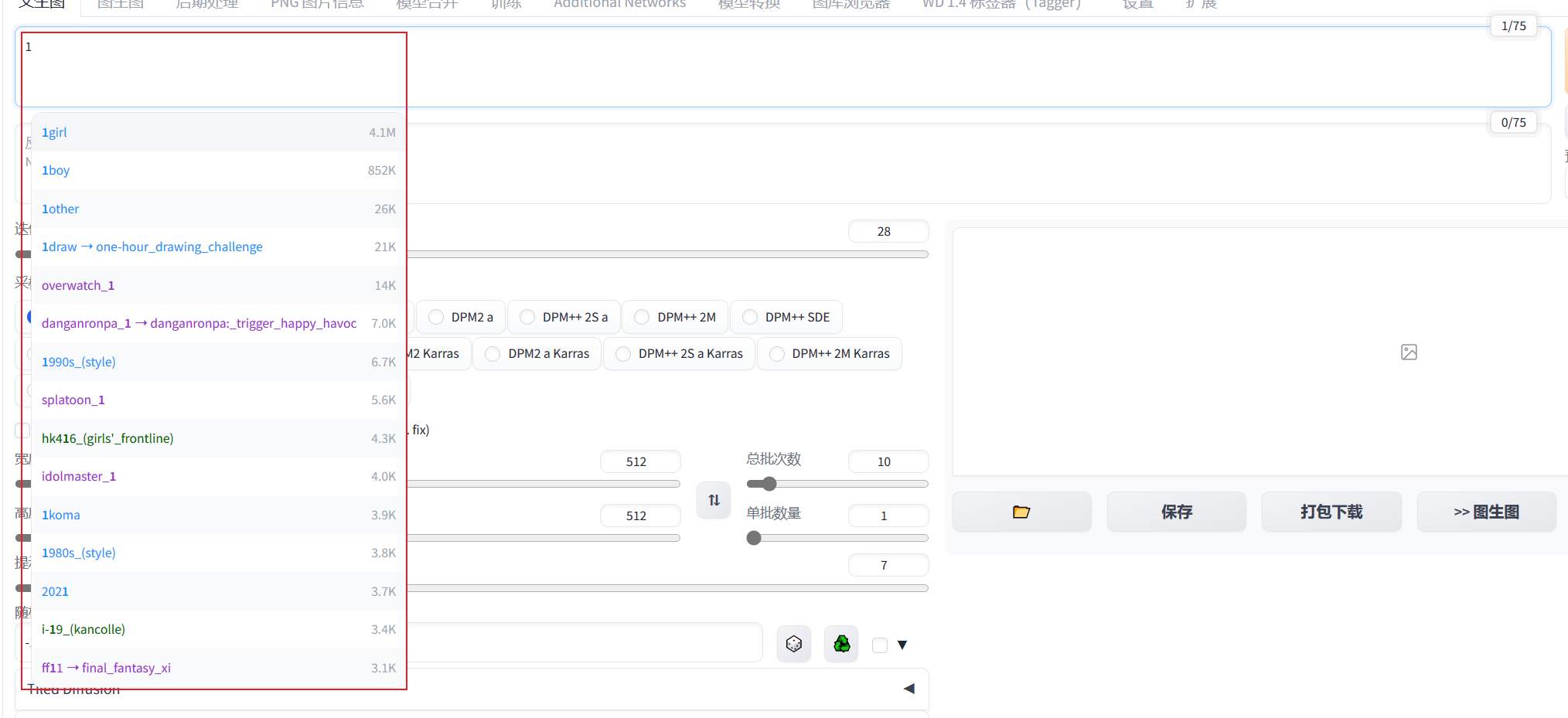
注意:如果没有提示这个标签,那它大概率是不会生效的,或者说你的模型库里还没有这个标签
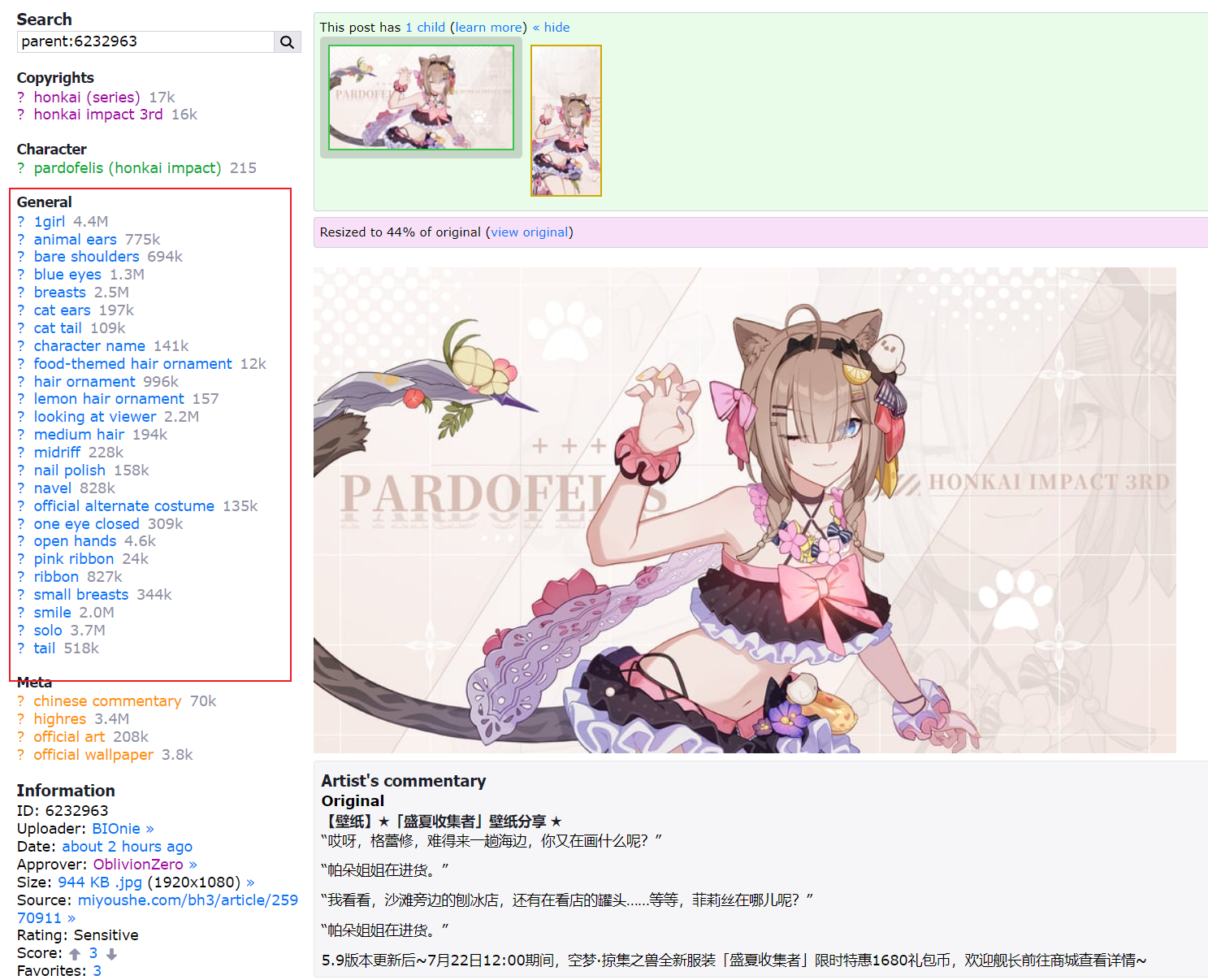
在Danbooru上查看图片包含的标签
进入网站选择或搜索你想要的图片,点击图片进入浏览就能看到图片标签:
在SD的WebUI上查看图片信息
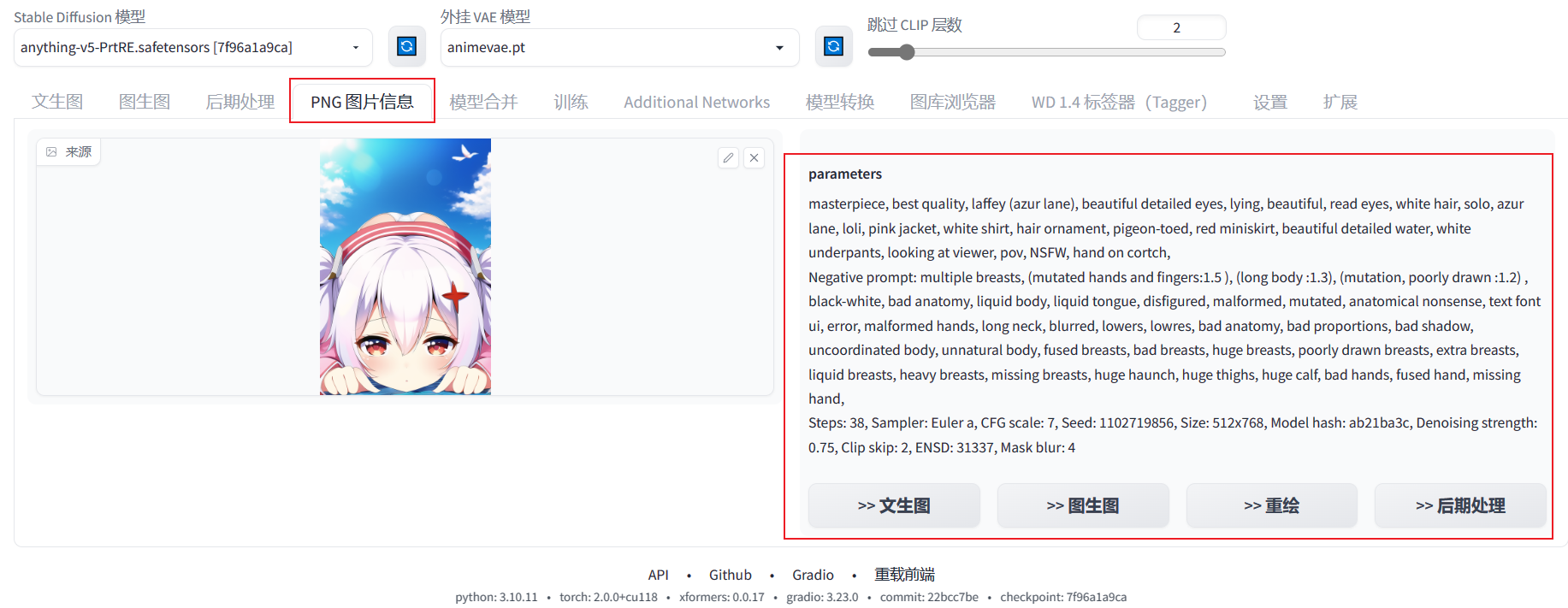
逆向获取
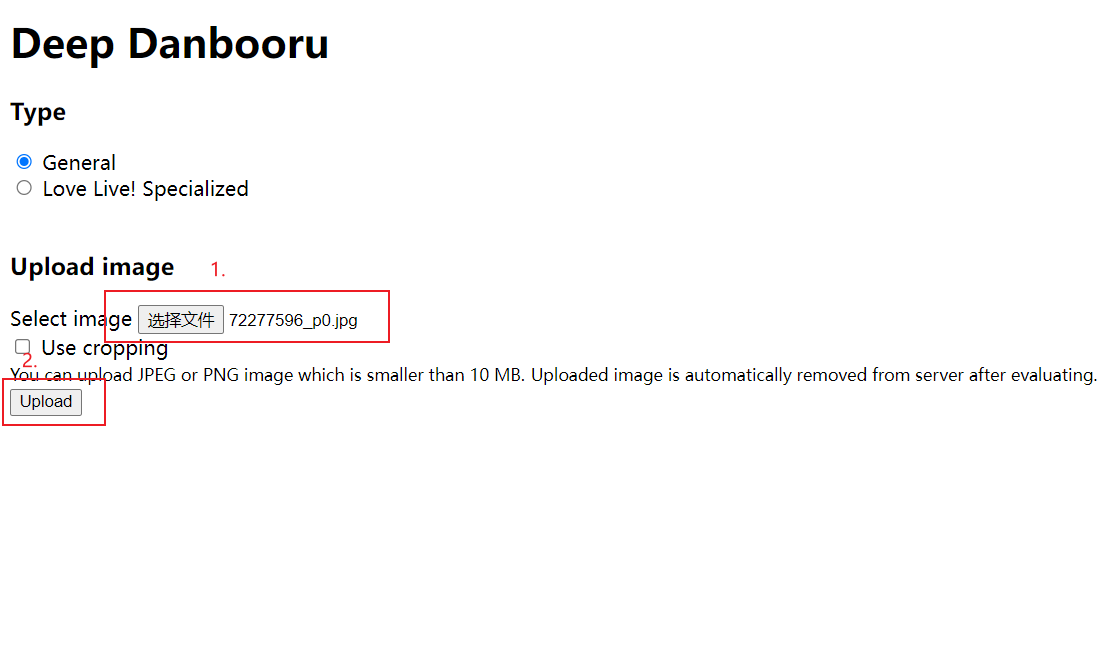
使用DeepDanbooru
用DeepDanbooruGitHub项目来识别图片标签:
简介:DeepDanbooru是一个Github上面的开源项目,你可以使用它们的在线网站进行测试,不过可能要魔法上网
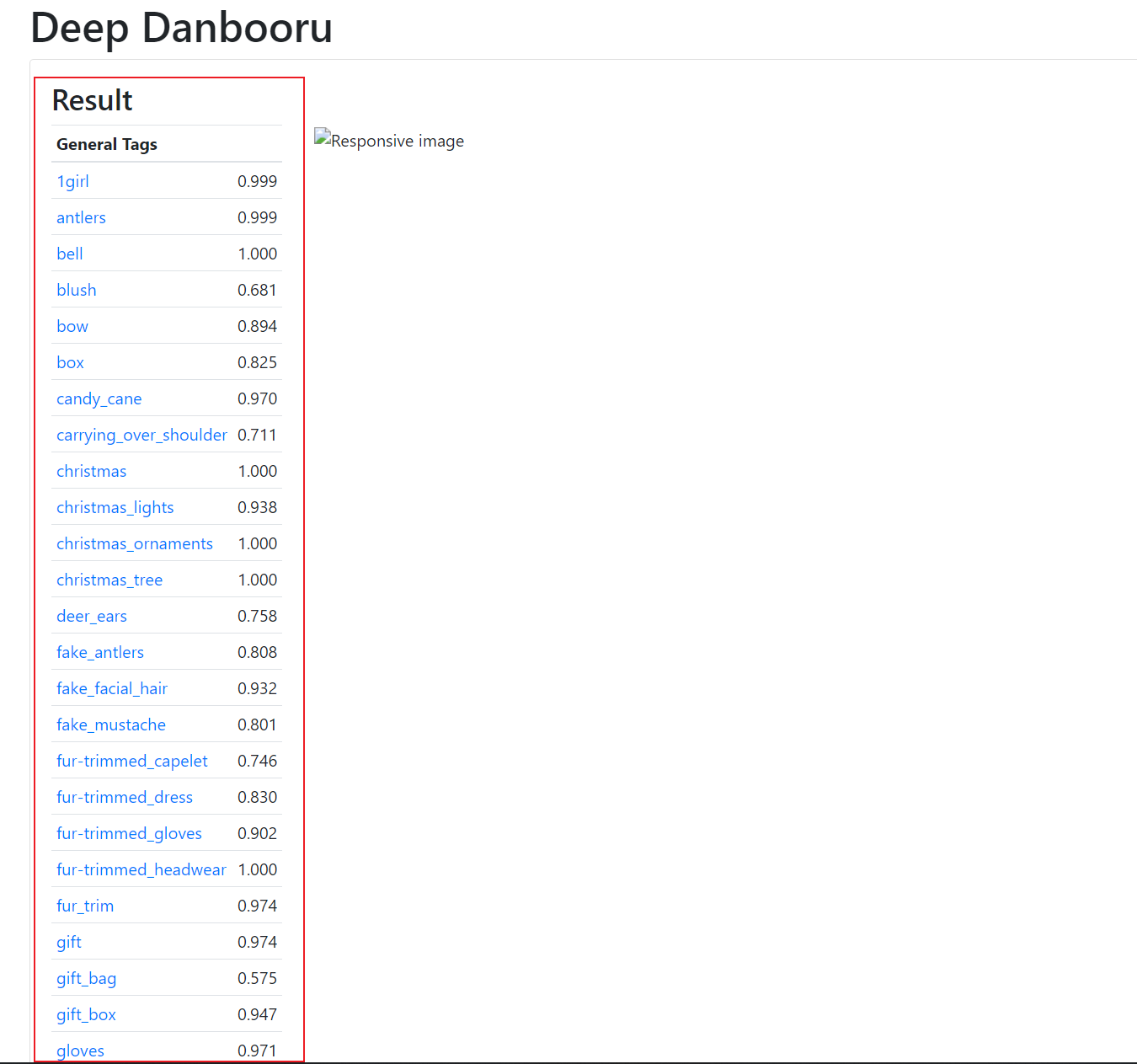
你可以看到左边的标签和右边的匹配程度,匹配程度越高判断越准确
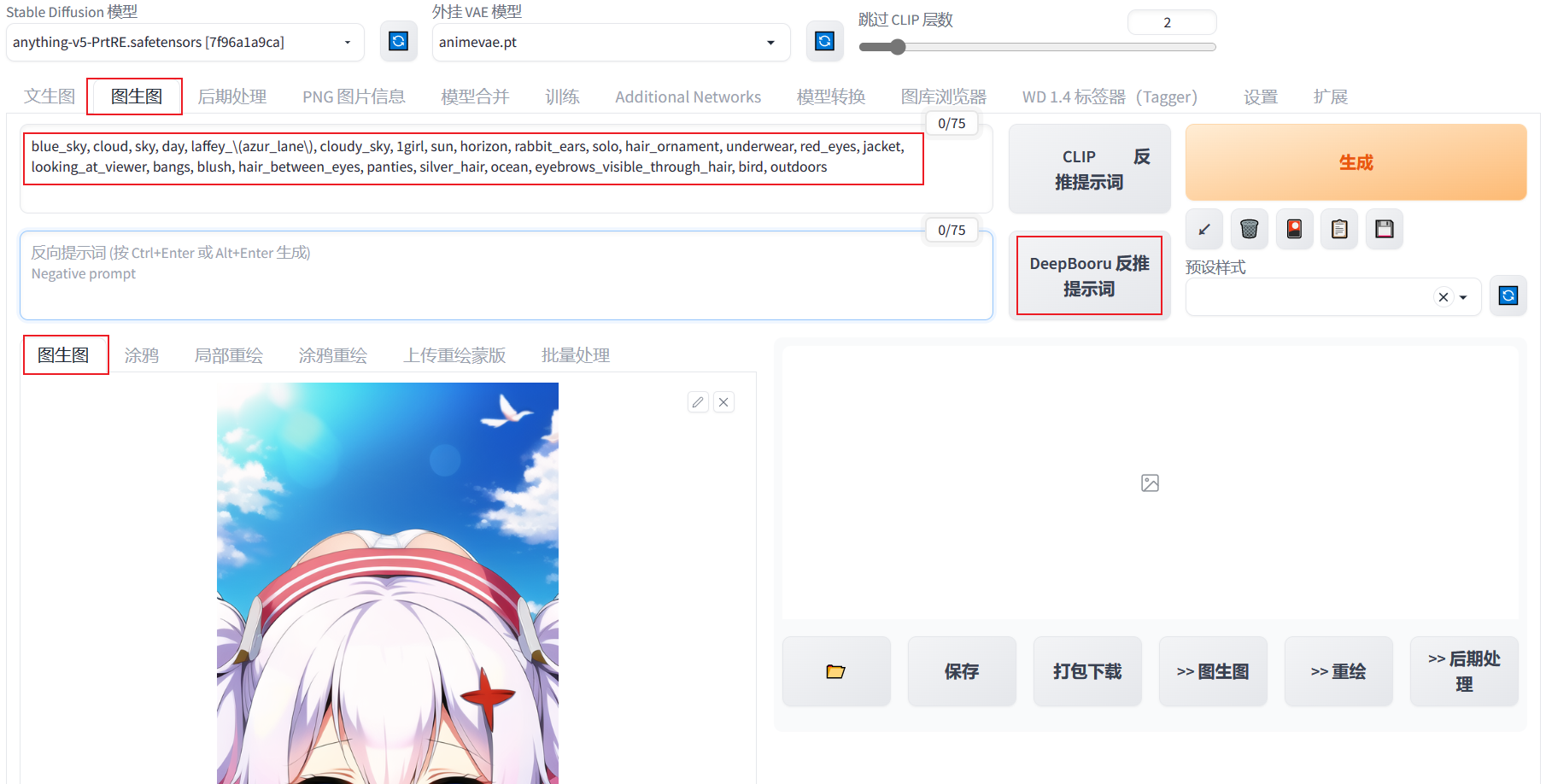
使用WebUI自带的DeepDanbooru:
使用WebUI图生图中自带的DeepDanbooru,注意不要使用CLIP,整合包上似乎没有这个插件
使用Tagger插件
整合包的SD默认自带Tagger,选择即可进入进行反推,运行速度较慢但是结果会比WebUI的DeepDanbooru准确
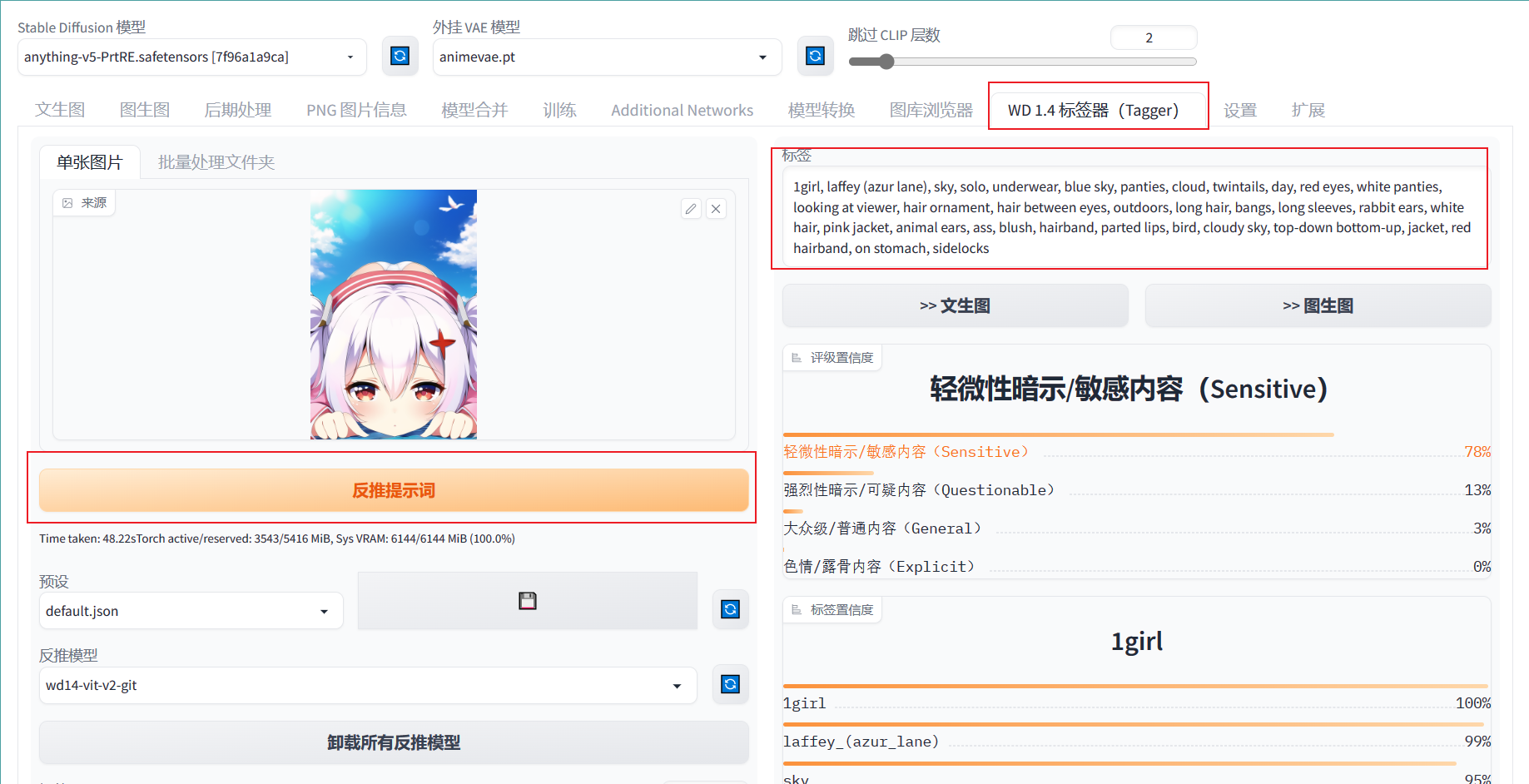
开始生成
简介:当你准备好标签后,就可以开始生成了
输入标签
这里抄下Danbooru 标签超市 (novelai.dev)元素法典的风魔法,你可以将这串标签粘贴进去来进行你的首次生成测试
正向:masterpiece, best quality, beautiful detailed sky, illustration, 1girl, solo, small breasts, ultra-detailed, an extremely delicate and beautiful little girl, beautiful detailed eyes, side blunt bangs, hair between eyes, ribbon, bowtie, buttons, bare shoulders, blank stare, pleated skirt, close to viewer, breeze, flying splashes, flying petals, wind
逆向:nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, missing arms, long neck, humpbacked, shadow, nude

变换参数
简介:SD中还有很多可以调整图片风格的变量,这里介绍一些主要的参数
这里借鉴一下大佬的图:
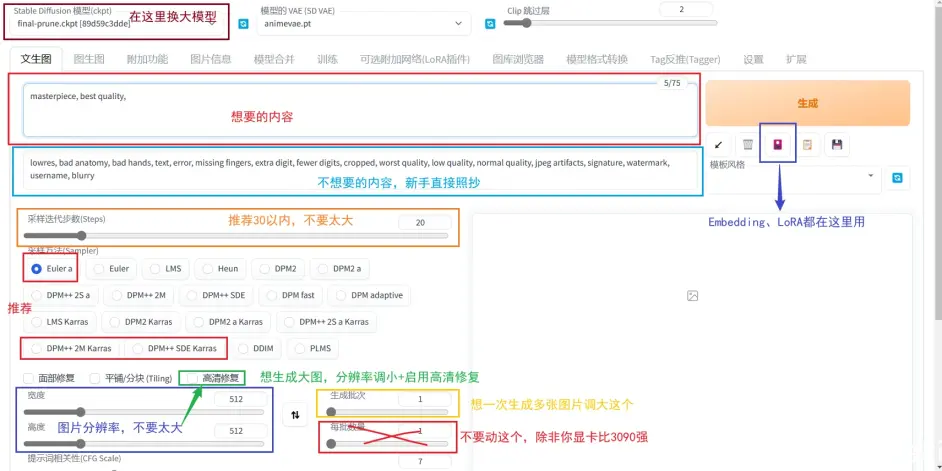
选择分辨率
可以使用Image Generation - NovelAI提供的几组分辨率进行绘画:
512*768、768*512、640*640、832*1280、1280*832、1024*1024、1024*1536、1536*1024、1472*1472、1088*1920、1920*1088
启动高分辨率修复
获取高分辨率的图片可以启用高分辨率修复。原始分辨率是768*512,修复后为1536*1024,可以在放大倍数里调整放大倍率
采样迭代步数
采样步数不要太大,一般选28步左右即可,采样次数大于30画面变化就很小了
采样器没有优劣之分,但是他们速度不同。全看个人喜好。推荐的是图中圈出来的几个,速度效果都不错

提示词引导系数:
提示词引导系数是指图像和标签的相关度,太低AI会自由发挥,太高会出现锐化线条变粗的效果。默认值为7
随机数种子:
随机数种子是一串随机数字,当关键词遇上这串随机数,图片就被生成出来。如果相同的标签和相同的随机数生成多次,得到的图片应该是相同的。这里随机数种子默认-1代表随机生成一串数字
使用X/Y/Z图表
简介:X/Y/Z图表可以让你直观的感受到参数对变量的影响,当然,你最多只能设置3个变量
资料:https://guide.novelai.dev/guide/configuration/param-advanced#x-y-z-图表
使用SD中的脚本选项找到X/Y/Z plot,可以选择X,X/Y,X/Y/Z,3种
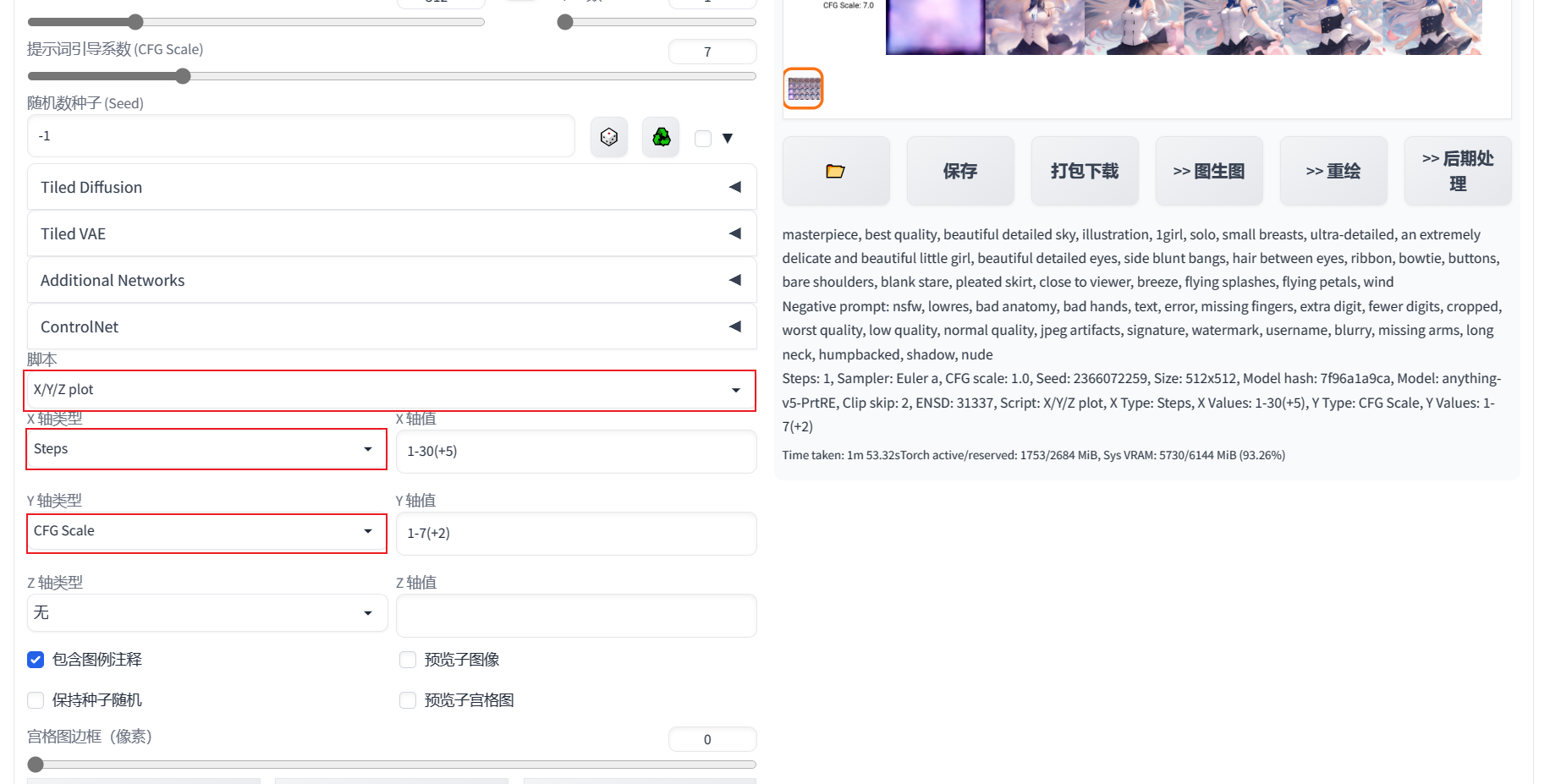
按照上图设置X轴为**步数(steps),Y轴为提示词引导系数(CFG Scale)**,可以得到下图的样式:

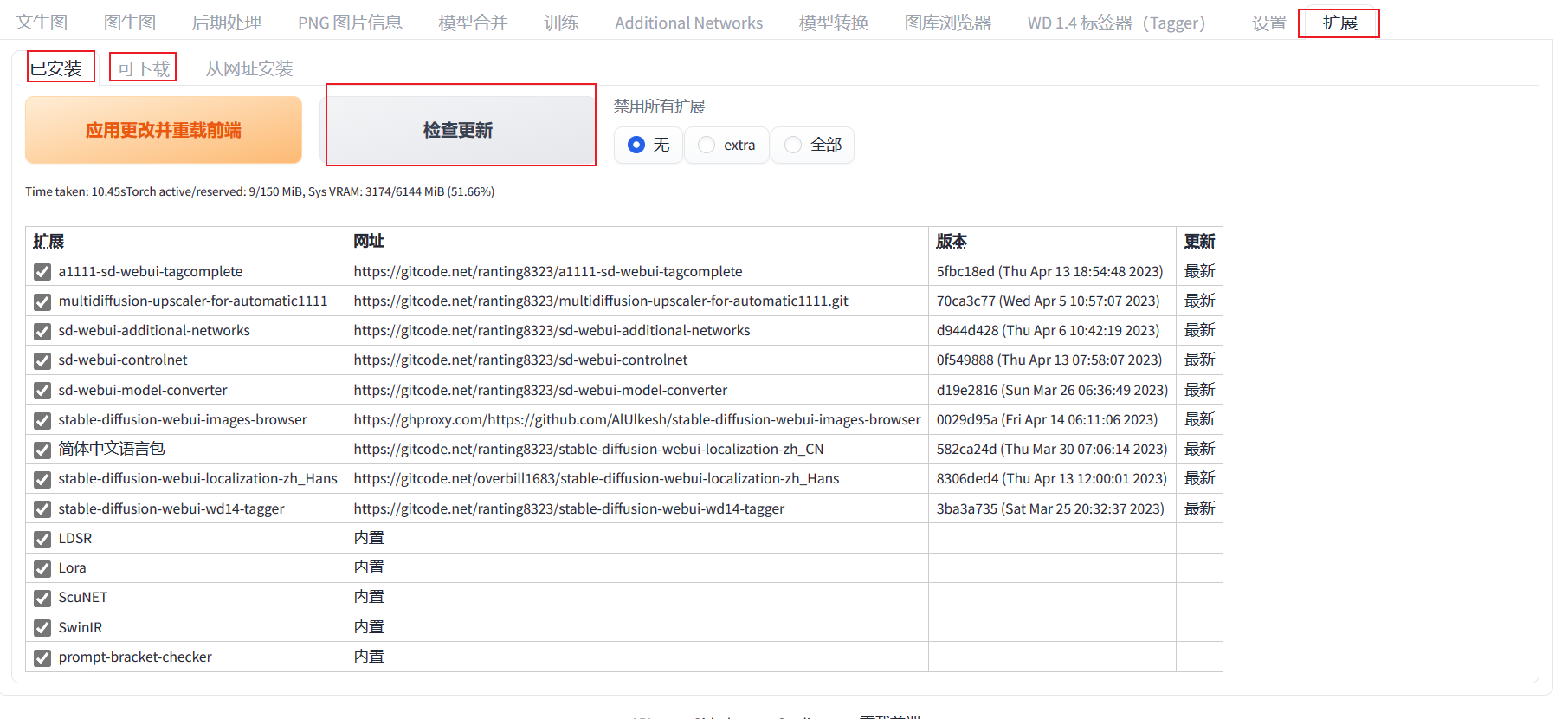
管理插件
简介:我们很多操作都依赖SD上安装的插件,包括SD的汉化。这些插件不是不可更改的,我们可以通过SD的WebUI界面来管理所有插件
操作:你只需要打开WebUI找到扩展,扩展中即可管理所有插件。你可以检查插件的更新,在可下载列表中安装新的插件
进阶
简介:你已经学会大部分基本操作了,但是AI绘画的重点永远是AI模型。你可能已经发现了现在的模型画风可以一眼识别出来是AI绘画的,于是怎么调整模型或者让画面看起来更像是一个画师画的呢?
资料:https://www.bilibili.com/read/cv21362202
认识模型
简介:不同的模型会带来不同的画风、认识不同的概念(人物/物体/动作),简单说就是有无这个Tag(标签)。这是模型众多的原因
去年泄露出来的NovelAI模型就是NovelAI制作的二次元特化模型,其模型数据大多数来自Danbooru和Twitter。NovelAI是一种大模型
当前模型可分为两类:大模型和用于微调大模型的小模型
模型后缀:.ckpt, .pt, .pth, .safetensors。前面三个后缀是pytorch的标准模型保存形式,由于使用了Pickle,有可能会被pickle反序列化攻击。最后一种后缀是为了解决前面几种模型的安全风险出现的,正如它名字中的safe一样安全。使用.safetensors需要把SD更新到2022年12月底以后的版本
注意:
- 你不可能用模型的后缀来判断模型的类型,因为模型后缀有很多。
- 模型大小不能决定模型质量
- 我不反对你使用模型,但请你尊重作者的版权和意向,不要将非商用的模型用来谋取利益,不要拿未经许可的图片来训练
你可以使用这个网址来识别模型类型:https://spell.novelai.dev/
大部分模型都能在civitai(C站)找到,国内需要魔法才能上:
了解大模型
简介:大模型指标准的latent diffusion(潜在扩散)或是它的进化版stable diffusion(稳定扩散)模型。大模型通常拥有完整的TextEncoder、UNet、VAE。简单说,大模型可以独立完成文字转图像的全过程
如果想深入了解可以参考这篇:https://zhuanlan.zhihu.com/p/617134893
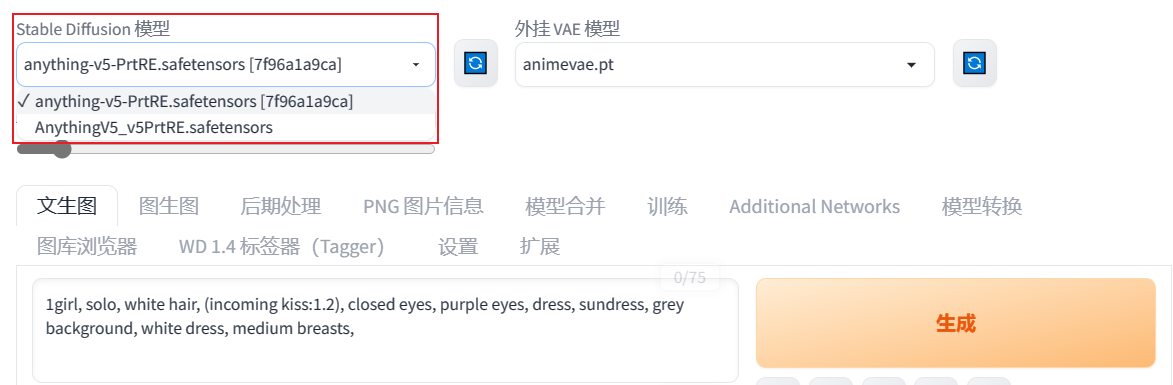
你可以在SD左上角选择Stable Diffusion模型:
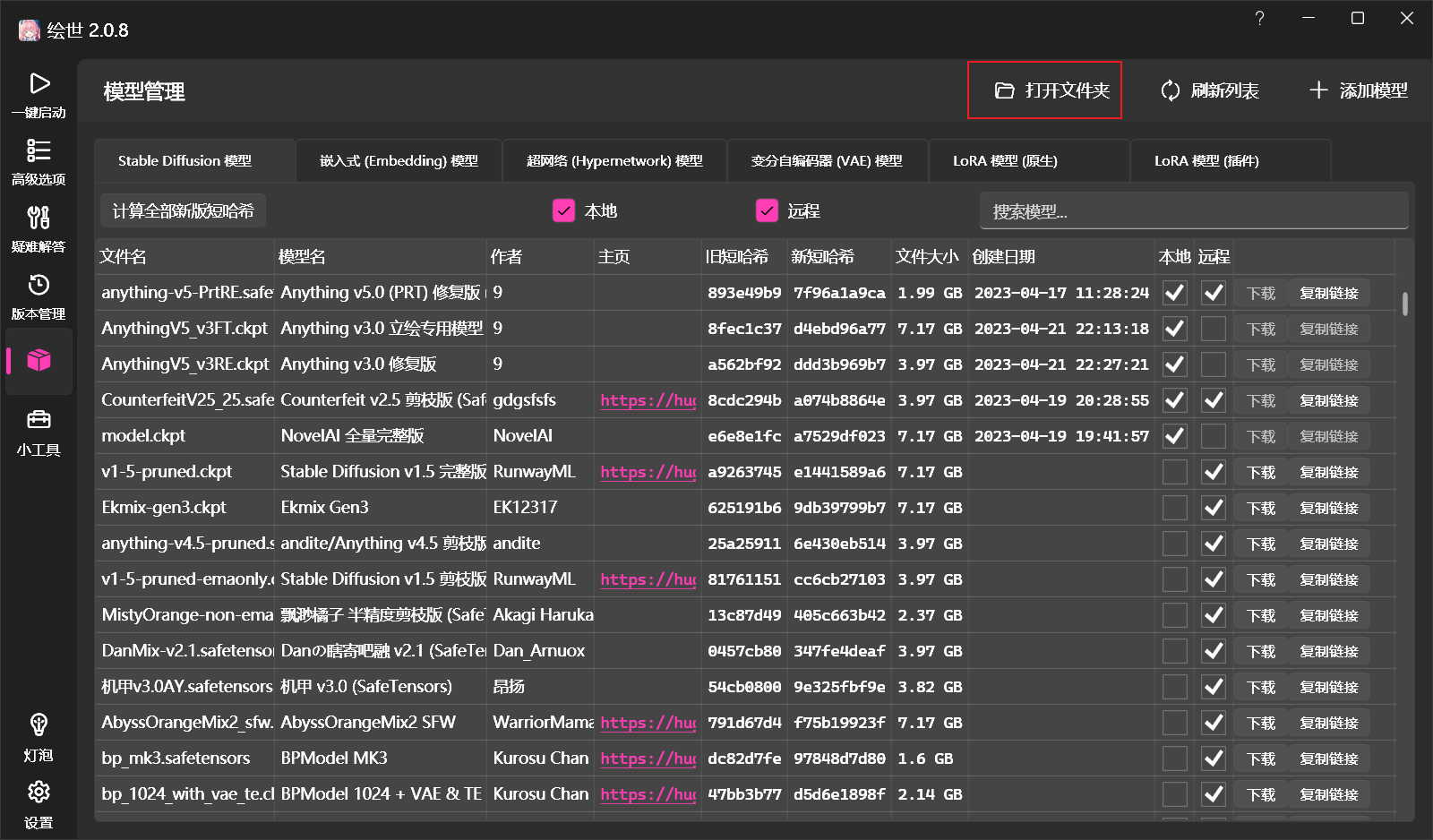
在SD中,大模型应该放在models\Stable-diffusion中,你可以从绘世的模型管理中打开:
你可以把里面默认包含的anything-v5-PrtRE.safetensors上传识别网站来验证一下,不出意外它应该会提示你为stable diffusion模型。如下图所示:

大模型的选择
简介:现在几乎所有AI绘画的模型都是从Stable Diffusion中再训练得到的,我在这里简单介绍我常用的模型
各大模型介绍链接:https://www.tjsky.net/tutorial/583
Anything v5(Prt-RE)&v3(RE,FT)



简介:Anything系列是一个叫9的大佬制作的。Anything v5是上述整合包里自带的模型,你可以在C站找到它。这个模型是在Anything v3的版本上增加了提示词的引导性
作者说为了图好看你可以选择Anything v3,所以你也可以选择再下载一个v3RE(修复版本)和v3FT(立绘专用版本)。Anything v3是一个传奇,它的出图质量堪比Novel AI商业模型,导致一段时间的炒作
Anything v3有着两个致命的弱点:手和眼睛高光
链接:https://civitai.com/models/9409/or-anything-v5
Counterfeit-V2.5

简介:Counterfeit模型是专为还原生活场景所打造的模型,它可以生成高质量的背景来配合人物,贴近真实而又具有动漫风格。简单说就是可以生成良好的背景与人物配合
链接:https://civitai.com/models/4468/counterfeit-v25
Novel AI
简介:Novel AI想必大家都清楚,就是它开创了二次元AI绘画文字转图片的潮流。当然你不清楚也没关系,你只要知道,它的网站在开放这个功能没多久就被脱裤了。而且后来面临许多官司,因为它的训练数据大多源于twitter和danbooru。其中很多图片都未经画师许可直接拿来使用
注意:Novel AI的数据库只泄露了一次,你可以自己去获得那个泄露出来的模型,但请你不要商用,不要发布。虽然你的图片经过处理可能也看不出是什么模型生成的,但我不对你造成的任何后果负责,我也不会给你任何途径来获取这个模型
Novel AI官网:https://novelai.net/image
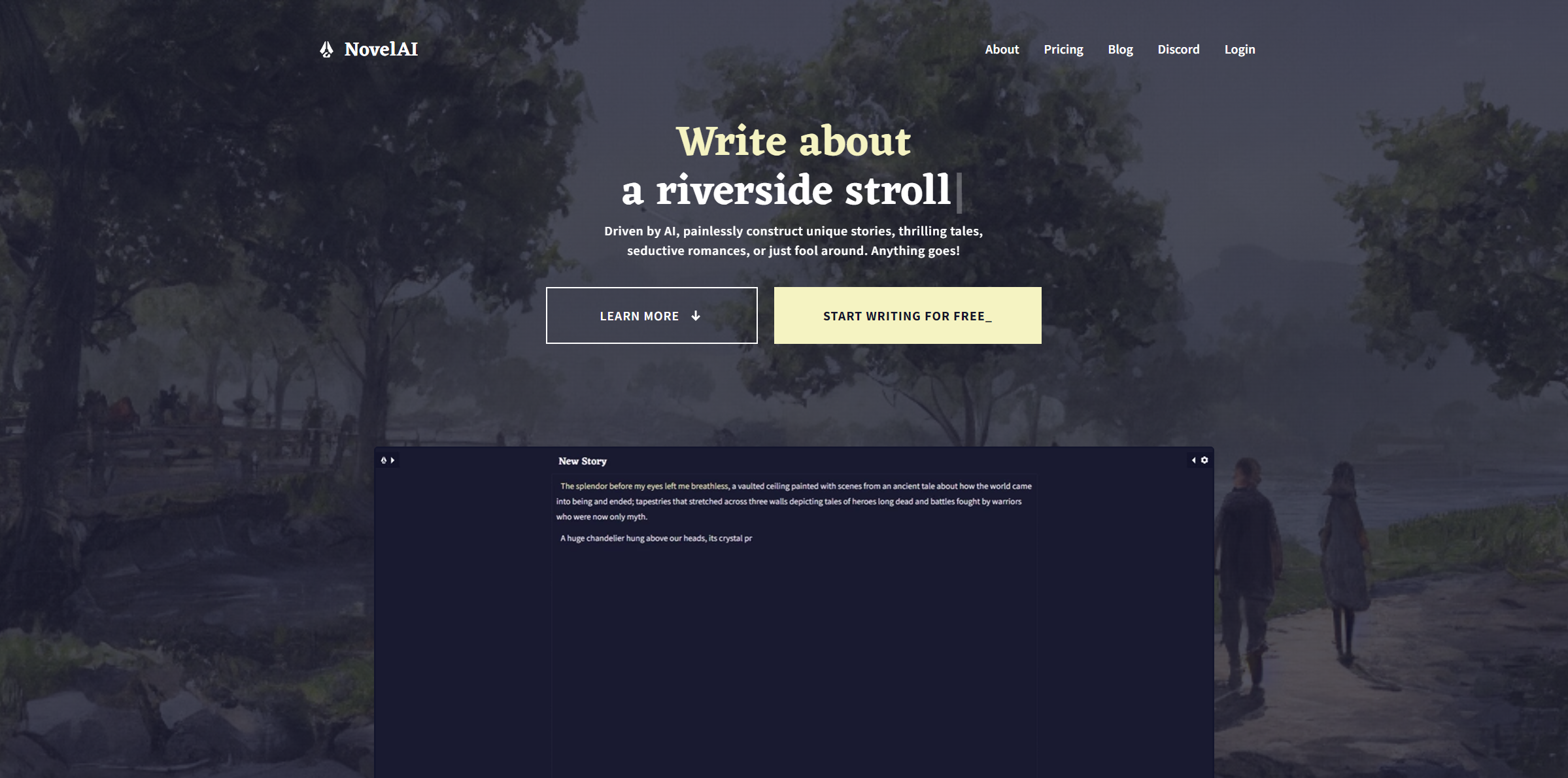
了解VAE

简介:VAE(Variational Auto-Encoder 变分自动编码器),你可以在SD模型的旁边来选择它。简单来讲就是一个解码器,用于给你的模型解码,解码越厉害,失真程度越低,画面越鲜艳真实。这里可以先简单理解成一个HDR滤镜:


上面两张图是用Counterfeit-V2.5生成的。这里可以看到,没VAE时色彩比较暗淡,也可以说是有失真,加了animevae后色彩丰富了起来。
VAE的选择
简介:选择VAE基本上就是为了调色,如果你生成的图片发灰,你可以添加或换个VAE去试试
流行的VAE:基本上就是模型管理的几个,你可以逐个尝试下。animevae.pt的泛用性是比较好的
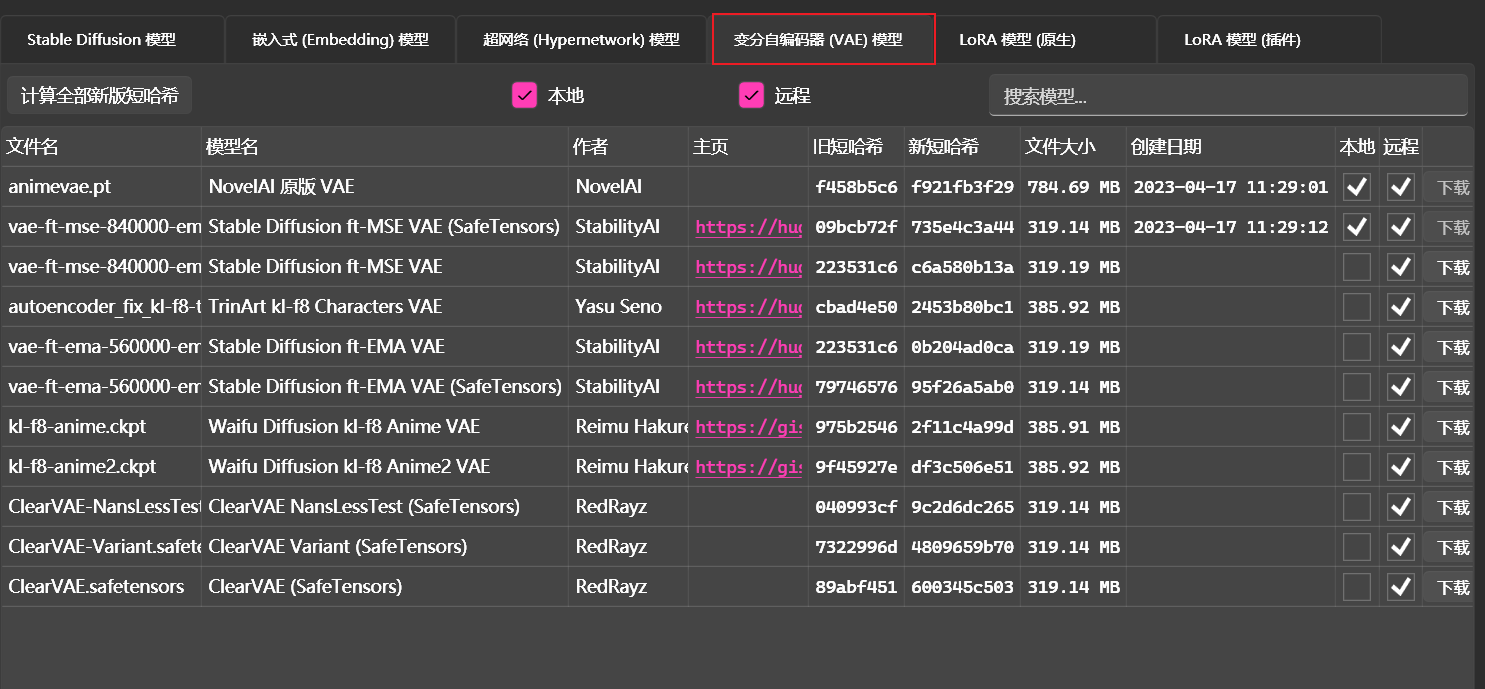
注意:有些模型有附加的VAE,但是C站不提供VAE标签,所以你最好去翻一下。例如Counterfeit-v2.5的模型库里自带一个vae,但是这个就是animevae改了名
了解CLIP
简介:CLIP(Contrastive Language-Image Pre-training 语言与图像的对比预训练)是一套模型,用于构建起自然语言(日常描述)与图片(图像特征)之间的预测算法。算法的作用就是将文字标签转换为图片特征。讲人话就是输入一个1girl,它就会给你只有一个女孩的图片。这种模型转换就是基于图片-标签集训练的,例如把danbooru的图片-标签集训练一下
链接:https://www.bilibili.com/read/cv19100966/
注意:CLIP一共有5层
clip skip的选择

简介:clip skip表示的是——在CLIP模型的最后N层终止(Ignore last layers of CLIP model),它的作用是选择图片和标签相关性。
默认选择:2
如果停止得太早,那么选出来的特征就会很多,生成的图片可能不会像标签输入的那样,AI就自由发挥了。如果只跳过1层,选出来的特征就会很精准,AI可以发挥的空间就少,图片也就越对应标签。
CFG Scale的选择
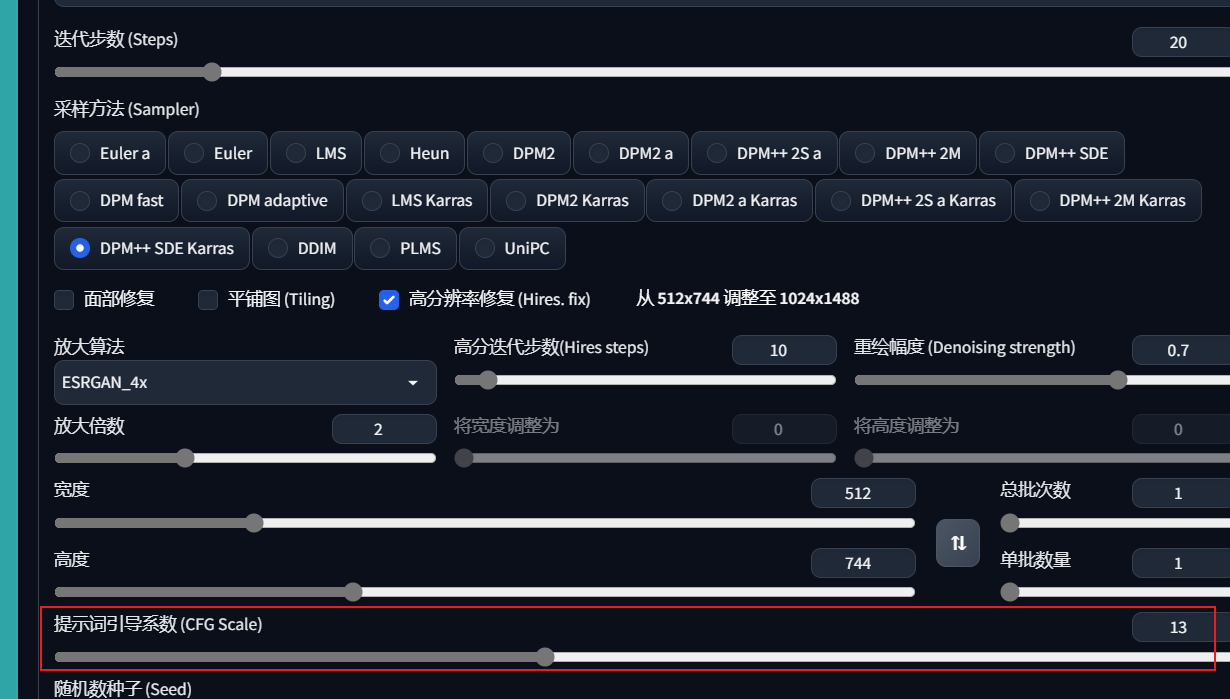
简介:图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示,但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。过高的 CFG Scale 体现为粗犷的线条和过锐化的图像。一般开到 7~11。超过13将发生色彩异化(显示不属于这个物体的颜色)
默认选择:7
注意:这个可以一定程度上和clip skip抵消,但是这两个值变化太大都会降低图片质量。
clip skip和CFG Scale的区别是:clip skip从源头上阻止不相关的图片出现,CFG Scale是挑选剩下符合的特征呈现
采样器
简介:在SD模型中,采样通常由模型和迭代步数组成。不同的采样模型通常含有不同的算法。一个标准的Stable Diffusion分为两个步骤;前向扩散过程,和后向的去噪、复原以及生成目标的过程。前向过程不断向输入数据中添加噪声,而采样器主要在后向过程中负责去噪的过程。
在图像生成前,模型会首先在Latent Space中生成一个完全随机的图像,然后噪声预测器会开始工作,从图像中减去预测的噪声。随着这个步骤的不断重复,最终我们得到了一个清晰的图像。
链接:https://zhuanlan.zhihu.com/p/621083328
步数
简介:采样步数很大程度上和你的采样器有关,但是采样步数造成的效果一般在40步以后就不明显了。采样的步数主要还是让你的模型充分收敛,使SSIM(Structure Similarity Index Measure) 结构衡量指标更接近1。SSIM是一个感知模型,越接近1则图像越真实
什么是SSIM:https://zhuanlan.zhihu.com/p/399215180
采样器的选择
简介:这里直接推荐哪个采样器更好用,要了解原理请参考上面两个链接
- DPM++ 2M Karras,Step Range:20-30
- UniPc, Step Range: 20-30
- DPM ++ SDE Karras, Step Range:8-12
- DDIM, Step Range:10-15
注意:
- 如果期望得到稳定、可重现的图像,避免采用任何祖先采样器
- 你最好看看链接里的模型收敛折线图,这个可以帮助你了解采样器的特性
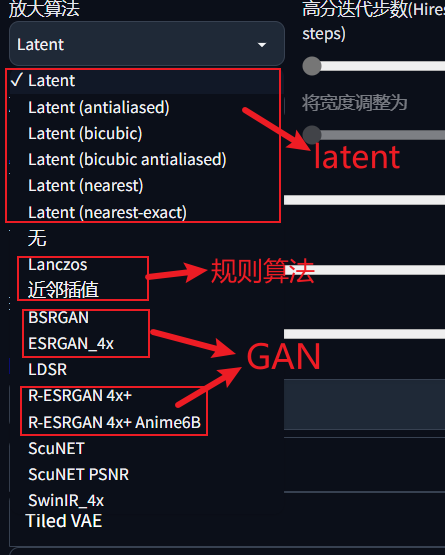
放大算法
简介:由于AI生成的图片分辨率都很低,而一下子生成高分辨率的图会把显存干爆,所以我们还要在一张模糊的低分辨率图上生成一张清晰的高分辨率图,这里我就讲几个主流的算法,其他算法可以自行查找
链接:
https://zhuanlan.zhihu.com/p/610346261
https://www.zhihu.com/question/585108915/answer/2965171166
表现:


分类:
高分迭代步数
简介:由于SD中许多放大模型都是基于AI计算的,AI计算就需要拟合才能出好的效果,所以需要有高分迭代步数
推荐设置:设置为10-20左右即可,一般不超过采样步数
Latent系列
简介:Latent Diffusion Models(潜在扩散模型)算法简称LDMs。该算法将图像特征压缩到低维,对图像进行低维扩散,再转换到需要的维度。
链接:https://zhuanlan.zhihu.com/p/562413185
推荐选择:就用Latent就行,不要用Latent+(xxx)的算法
评价:重绘幅度大时比较好看,可能会大幅度改变原图。注意重绘幅度设置为0.6-0.8
GAN系列
简介:GAN(生成式对抗网络)是一种专门用来绘图的AI算法,ESRGAN是BARGAN的改良版
推荐选择:R-ESRGAN 4x+,R-ESRGAN 4x+ Anime6B(二次元定制版,有轻微的羽化现象)
评价:重绘幅度小时好于Latent,不想大幅改变图片可用
规则算法
简介:规则算法是指基于某种规则放大图片的算法,由于图片非常灵活,规则算法除了运算快基本没有用武之地,除非图片十分规则
评价:最好不用
LoRA
简介:LoRA是一种画风导向模型
教程:https://www.bilibili.com/video/BV1Py4y1d7eJ
这个更新了,现在你可以直接将模型放到models/Lora文件夹下了,待更新
control net
简介:control net主要是控制模型细节
教程:https://www.bilibili.com/video/BV1fa4y1G71W
待更新

